
Web application performance is one of the most important topic nowadays. Most of us create application that have to be fast not only on desktop but also on mobile devices. Mobile network is slow and this causes that we have to think about performance constanly. One of technique that we can apply in our application to make it faster is HTTP caching. I'm going to show you how we can use this technique in Rails application.
HTTP Headers
Browser and server are really talkative and they like to share knowledge about web pages and other resources. During every request and response, browser and server exchange data as HTTP headers. HTTP header contains the name of the header and its value (string). The easiest way to check the headers and theirs values is opening the developer console in a browser (in Chrome you can find them in Network -> Headers tab):
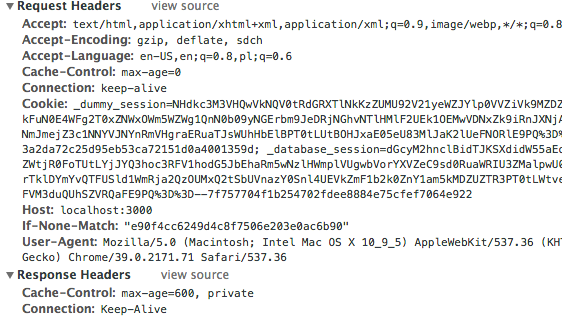
The headers which are interesting for us are:
- Last-Modified (response header) and If-Modified-Since (request header)
- Etag (response header) and If-None-Match (request header)
- Cache-Control (response header)
Let's look at them separetly.
Last-Modified/If-Modified-Since
Let's say that browser asks server for page first time (we never visit the page before). Server sends the response (for example generated HTML page) with status 200 and it can also set HTTP header: Last-Modified. This header should contain the date of last modification of the page:
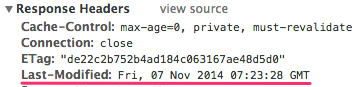
When browser finds this header in the response, it gets the header's value and caches it. When the browser asks server second time for the same page, it sends this cached value in the HTTP header: If-Modified-Since

This way browser asks the server: "Is the page being modified since the last time I saw it?". When server finds the If-Modified-Since header in the request, it can compare the value from the header with last modified value for the page. If they are the same, the server sets response status to 304 and it sends to browser empty response body. When the browser gets reponse with this status, it renders the page from cache.
What are the adventages of this behaviour? First and foremost, we decrease the response bandwidth, as with 304 status, server sends to browser empty body in response. This, of course, makes page rendering faster. The second adventage is that we control browser cache. The third is that we might reduce view rendering on the server side, but this is not the default behaviour that Rails provides us. We have to do some settings by ourselves. I'll talk about later in this article.
As always there are also disadventages: the browser can't decide without server that it can take page from cache. So the browser always have to make request to server, which, again, takes time.
ETag/If-None-Match
The way how these pair of HTTP headers works, is similar as described above. The difference is that, when browser asks server for a page first time, the server sends ETag HTTP header. The header contains the hash (md5) from page's HTML:
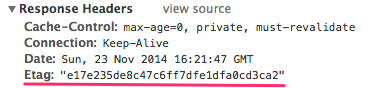
The browser caches it and when asks server for the page again, send this cached value to server in If-None-Match HTTP header. This way the browser asks server: "I have this version of the page. Is is still the same?". The server compare hash from the request header with the new one, generated from the actual page content. If they are the same, the server sets 304 status on response and clears body content in response. Otherwise, the server sets 200 status and sends back HTML page in response body.
The pros and cons usege of these headers are exacly the same as with Last-Modified/If-Modified-Since headers.

Cache-Control:max-age
Cache-Control is the header which is sends in the response by the server. It contains different keys (sometimes with values), separated by commas. In this header the server tells browser how long the page (or other resource) will be actual:
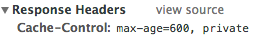
This header has big advantage compares to other ones. Here browser has knowledge how long the page is actual, so the browser doesn't have to request the server. The browser can take the page from cache immediately, so this is super fast!
The cons is that in many situation is hard to estimate the time how long the page should be valid.
Ok, so now we know how these HTTP headers work. Let's see how Rails helps us to use them more easily.
Rails, as usual, does a lot by default!
Rails has by default two middlewares that helps with ETag/If-None-Match headers:
- Rack::ETag
- Rack::ConditionalGet
When you run
rake middlewareyou can see them up to the bottom of middlewares stack. Let's dig into source code of this middlewares and understand how they work. You can find the code in rack gem. So let's open it. In your console, go to the directory with Rails project and run:
bundle open rackSidenote: if you are using Sublime text, you can open any gem from editor with this plugin: https://github.com/NaN1488/sublime-gem-browser.
rack is the gem that is installed with rails gem. When you open the gem in an editor, go to lib/rack directory and open etag.rb file. The important is call method, which is called when request/response goes throught middleware stack.
1 # gem rack - lib/rack/etag.rb
2 def call(env)
3 status, headers, body = @app.call(env)
4
5 if etag_status?(status) && etag_body?(body) && !skip_caching?(headers)
6 digest, body = digest_body(body)
7 headers['ETag'] = %("#{digest}") if digest
8 end
9
10 unless headers['Cache-Control']
11 if digest
12 headers['Cache-Control'] = @cache_control if @cache_control
13 else
14 headers['Cache-Control'] = @no_cache_control if @no_cache_control
15 end
16 end
17
18 [status, headers, body]
19 endIn the line 6, digest from response body is created. If you look into digest_body method, you can see that Rack::Etag class uses md5 algorythm to generate it. Next, in the line 7 - header ETag is set. So this middleware sets up the ETag header for us.
Let's see what Rack::ConditionalGet buys us. You can find source code of this class in lib/rack/conditionalget.rb file:
1 # gem rack - lib/rack/conditionalget.rb
2 def call(env)
3 case env['REQUEST_METHOD']
4 when "GET", "HEAD"
5 status, headers, body = @app.call(env)
6 headers = Utils::HeaderHash.new(headers)
7 if status == 200 && fresh?(env, headers)
8 status = 304
9 headers.delete('Content-Type')
10 headers.delete('Content-Length')
11 body = []
12 end
13 [status, headers, body]
14 else
15 @app.call(env)
16 end
17 endIn the line 6, it checks if the response status is 200 (so we have success). The second condition (fresh?(env, headers)) checks if the the pairs of headers Last-Modified/If-Modified-Since and ETag/If-None-Matchmatch each others. If so, (in the lines from 7 to 10), the status is set to 304, HTTP headers Content-Type and Content-Length are removed and the response body is cleared. As we can see this middleware is responsible for setting 304 status and clearing body, if the browser has actual content for the page.
So you can think right now: "Rails do all the hard work for me. So why to bother this topic, except that good to know how it works?". The thing is that we can go step futher and make it better. As I mention earlier, when we generate ETag/Last-Modified we can also reduce view rendering on the server side. Let's see how we can make it.
stale?/fresh_when methods
In controller's class, Rails gives us two instance methods:
- stale?
- fresh_when
Above methods allow us to easily generate Etag and Last-Modified headers on the application level. Let's see how we can use them.
Varbose example of stale?
1 def show
2 @book = Book.find(params[:id])
3 if stale?(last_modified: @book.updated_at, etag: @book)
4 respond_to do |f|
5 #standard rendering
6 end
7 end
8 endWe can also use shorter form of stale?
1 def show
2 @book = Book.find(params[:id])
3 respond_with(@book) if stale?(@book)
4 endfresh_when works in different way. Verbose example:
1 def show
2 @book = Book.find(params[:id])
3 fresh_when(last_modified: @book.updated_at, etag: @book)
4 endand concise example:
1 def show
2 @book = Book.find(params[:id])
3 fresh_when @book
4 endNow lest look closer how these methods work. Both of them take hash as an argument.
last_modified - the value of this key will be the value of Last-Modified header. So it must be a datetime. etag - not surprisingly value of this key is used by Rails to generate Etag header. Let's look into source code to check what values is can take:
1 # gem activesupport - lib/activesupport/cache.rb
2 def retrieve_cache_key(key)
3 case
4 when key.respond_to?(:cache_key) then key.cache_key
5 when key.is_a?(Array) then key.map { |element| retrieve_cache_key(element) }.to_param
6 when key.respond_to?(:to_a) then retrieve_cache_key(key.to_a)
7 else key.to_param
8 end.to_s
9 endWe have quite wide range of options here:
- we can set an object here, that responds to cache_key message. All ActiveRecord objects have this method defined by default.
- we can set Array of objects or the object that responds to to_a message
- finally, if nothig match (for example when the key is a string), the to_param method will be used
If you are curious how the generated ETag value looks like, here is the example. For Book model cache key may look like this:
1 books/2-2014112812345- books - the name of the table for model
- 2 - model id
- 2014112812345 - timestamp from updated_at attribute by default
The params hash for these methods can also have public key set (by default it has false value). When it is set to true the reponses from our application can be cached by other devices (proxy caches).
The more concise form of these methods takes just object. If so, the object must response to cachekey and createdat methods.
What you should remember when you generate HTTP headers in the application?
The rule of thumb is: always think about all elements on the page that are changing. If the UI depends of them - they should be taken into account when you generate ETag and Last-Modified headers.
Page contains a form
When a page contains a form, you have to remember about authenticitytoken that is send with request when an user submits the form. This token is changing so have to pass it to etag option when we generate ETag. In a controller, you can use formauthenticity_token method to retrieve
1 def edit
2 @book = Book.find(params[:id])
3 fresh_when last_modified: @book.updated_at,
4 etag: [ @book, form_authenticity_token ]
5 endPagination
Another frequent situation is pagination on a page. Generating ETag we have to take into account two things:
- the amount of elements in a collection
- the updated_at attribute for elements in the collection. In fact, we don't have to worry about every single object in the collection. The most important for us is the last element that was updated.
1 def index
2 @book = Book.order(:title).page(params[:page])
3
4 count = Book.count
5 # remember to create index on update_at field
6 updated_at_max = Book.maximum(:updated_at).try(:utc).try(:to_s, :number)
7
8 fresh_when etag: "books/all-#{count}-#{updated_at_max}"
9 endPropagate updated_at to owning objects
Sometimes the state of a page doesn't depend on object state directly. Les't assume that the show page of the book, contains user's comments. The comment model looks like this:
1 class Comment < ActiveRecord::Base
2 belongs_to :book
3 belongs_to :user
4 endWhen we create ETag for show page in the standard way:
1 def show
2 @book = Book.find(params[:id])
3 fresh_when etag: @book
4 endit won't work properly. When a new comment will be created, the ETag will be still the same and the browser will get 304 status. We have to change Comment model:
1 class Comment < ActiveRecord::Base
2 belongs_to :book, touch: true
3 belongs_to :user, touch: true
4 endThe option touch causes that everytime a comment is created or updated, the updatedat attirbute on associated models is also updated. This way if a new comment is created, the updatedat attribute for book will change and the value of ETag and Last-Modified will also change.
Values in session
There are values that are not depenedent on updated_at attribute, but have an influence on our page. For example:
- flash messages
- current_user attributes
- cookies
Fortunately, Rails can help to solve this problem. In contoller class we can use class method etag, which allows us to define global values to compose ETag.
1 class ApplicationController < ActionController::Base
2 etag { flash }
3 etag { current_user.try(:email) }
4 endWhen you have many data in session and it will be hard to chose what takes to ETag, you can take the whole session:
1 class ApplicationController < ActionController::Base
2 etag { Hash[session] }
3 endHTML or CSS changes
Whet you do in situation when nothing changed in your model, but HTML or CSS changed. Of course, you want the visitors to see the newest version of the page. How can you tell Rails to invalidate ETag header ? By default, when Rails generates ETag value it can add additional prefix to it. This prefix is a value of RAILSCACHEID or RAILSAPPVERSION environment variables. So everytime you want to invalidate etags, you can just change the values of this variables.
expires_in
Finally, let's see how we can set Cache-Control:max-age. We have a special method in controller to our disposal - expires_in:
1 def show
2 @book = Book.find(params[:id])
3 expires_in 10.minutes
4 endSummary
Rails helps us a lot to manage HTTP headers. It's definitely worth to use HTTP headers, even if you only depend on default behaviour of rack meddlewares.